AI Scraper by Parsera: n8n User Manual
AI Scraper is an n8n community node. It lets you use the Parsera AI Scraper API in your n8n workflows to extract web data with a prompt.
🔩 Install & Setup in n8n Cloud
- Install Node: search n8n for 'AI Scraper' or 'Parsera' and install the node
- Get API Key: create an account at Parsera.org, then log in to get your API key
- Connect n8n: use your API key to set up 'New Credentials' in n8n
- Check VIDEO below: we show how it works there: Watch on YouTube
🌐 Extract from URL (Extractor)
- Extractor uses an LLM for every scrape, adapting to your request and page layout. Ideal for unique URLs.
- Learn more about it, especially
how to prompt correctlyin Extractor Manual
Setup:
- Provide URL: ensure the URL is valid (URL should always start with
httpORhttps)

- Prompt: give the scraper general instructions and context (optional)
- Attributes Input Mode: is more detailed prompt that ensures more consistent and accurate data extraction (⚠️ always scrape with attributes)
- Fields: give the scraper specific context for each field (future column with your data)
- Field Name: (e.g.,
product_name,price) - Type: the expected data type (e.g.,
string,integer,number,boolean,list,object,any)(optional)- ⚠️ Sometimes not-relevant data type can cause errors
- Field Description (Prompt): tell the AI what data to look for (e.g.,
"Get price of the product","Get the discount, in other cases, put 'no discount'")
- Field Name: (e.g.,
- Fields: give the scraper specific context for each field (future column with your data)

- JSON: Define attributes as a single JSON object
- The expected format is
{"product_price": {"description": "Get price of the product", "type": "number"}}
- The expected format is
- Mode:
- Standard: ideal for most of the cases
- Precision: extract data hidden in HTML tags
- Proxy Country: select a country for geo-restricted content (optional)
- Cookies: optionally provide cookies as a JSON array to be sent with the request (e.g., for authenticated sessions). Format:
[{"name": "cookieName", "value": "cookieValue", "domain": ".example.com"}]
📑 Parse HTML (Extractor)
Provide raw HTML content, and Parsera will parse it to extract data based on your defined attributes
Setup
To set up the HTML Parser, follow the steps for 'Extract from URL,' but paste your HTML content instead of a URL into the relevant field
🤖 Scrape with Agent
- Agent uses LLM only ONCE to generate a reusable scraping script based on the successful usage of Extractor on certain page layout.
- Being non-dependent on LLM makes Agents perfect for SCALE (e.g. 📦 Scrape 5k product page of sneakers on www.ebay.com OR 📦 Scrape events on www.meetup.com every 24h)
Setup
1. Create Agent
- The agent itself must be created separately before it can be used in n8n. It can be done via parsera.org OR Parsera API.
- Learn Why and How to create Agent in Scraping Agent Manual.
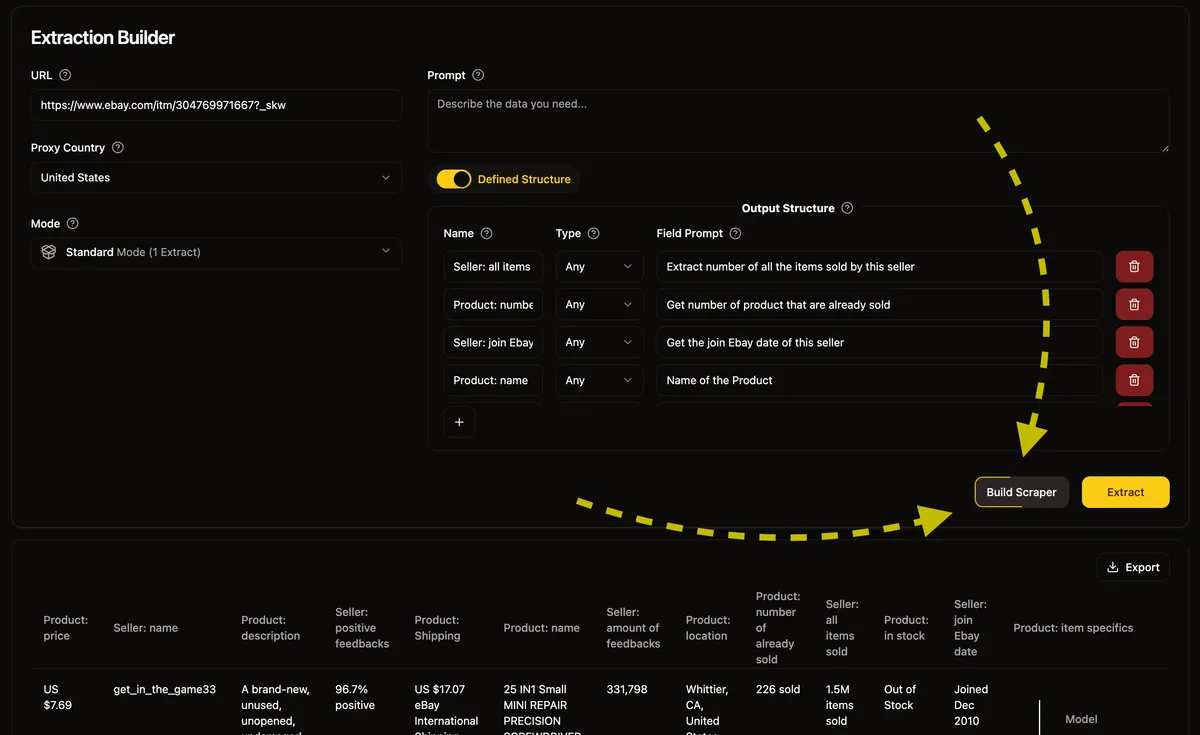
2. Setup Agent in n8n
- Agent Name: go to the page of your Agent on parsera.org copy Agent's ID (e.g.
ebay_product_page_scraper) and use in n8n as 'Agent Name'

- Provide URL: ensure the URL is valid and matches the structure of the original URL (URL should always start with
httpORhttps)
Thank you for reading AI Scraper n8n Manual 🎈
If you have any question email me OR book a call