Extractor Manual 📦
Extractor is an LLM-powered tool designed to analyze web pages with different layouts to scrape data based on provided natural language instructions.
What can I scrape using it?
- Structured data fields: name, price, contacts details and other attributes
- URLs: PDFs, images, pages
- Unstructured data: quotes, summaries, insights and other contextual data from long-form texts
- Authenticated Data: via Cookies
⚙️ How to set up Extractor? (VIDEO)
✏️ Step #1: Describe
URL
- URL: Ensure your data is present on the page, before click
Extract - Proxy Country: Content on the web-page can vary from the country so pick proxy country accordingly
- Mode: Standard — ideal for most of the cases
You can only scrape data from the specific page whose URL you provide, not the entire website
Data
You can extract data using the Prompt field, the Output Structure table, or a combination of both.
⌨️ Prompt field
- Use the Prompt alone for simple extractions (up to 5 data fields) with no special formatting or filtering.
- You can also use it for generation an Output Structure.
🖥️ Output Structure table
-
The Output Structure table allows you to define specific data fields and specify how each should be formatted.
-
It ensures your instructions are interpreted clearly by the LLM, reducing the risk of hallucinations, improving accuracy, and reliability.
❗️ Use Output Structure for complex scraping cases such as:
- You need to extract more than 5 fields
- You require conditional scraping
- You need to specify the data position on the layout
- You want to customize how the data appears in the output
💡 Prompt + Output Structure (Recommended)
- Use the Prompt to describe in plain language what you want to scrape.
- Use the Output Structure to define the exact fields and formatting rules.
- For complex fields, add specific prompts to guide the Extractor.
- For simple fields, you can leave the prompt blank—the Extractor will rely on the main Prompt for context.
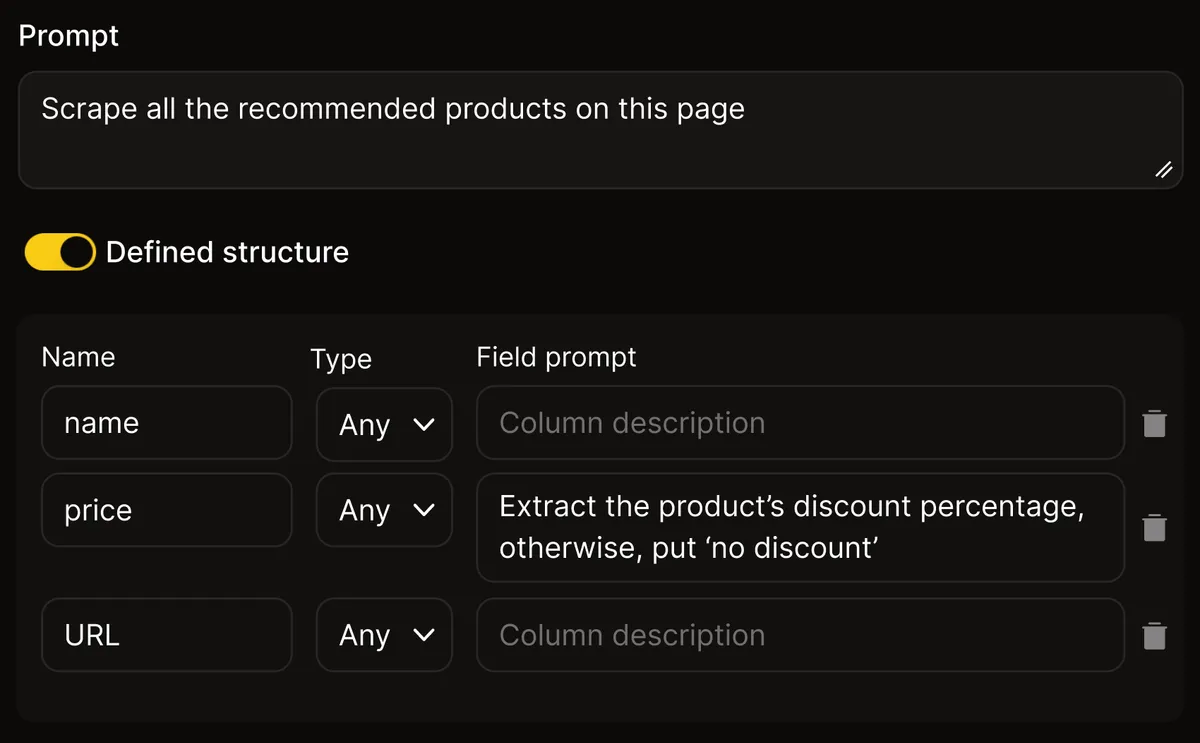
ℹ️ Example:
💎 Step #2: Refine
At this step, focus on refining your Extractor request to get the most accurate and reliable scraping results, especially if you plan to reuse the extractor for more URLs or scale it into a Scraping Agent:
- Double-check: Run several test extractions to ensure the results are consistent.
- Be specific: If some data looks incorrect, try to pinpoint its exact location on the page layout
(e.g. an e-commerce product page might have two different "product info" sections with different features). - Polish: You can adjust how the data is presented in the output, including its format. Just keep in mind that using the wrong data type can sometimes cause errors.
🦾 Step #3: Automate
If you're happy with the data Extractor returns after several extracts, you can automate the scraping using one of these methods:
- Automation Tools (n8n, Zapier, Make): Run Extractor on multiple URLs as part of your workflow in n8n, Zapier, or Make
- API: Send a batch of URLs via API.
- Generated Scraper (Scraping Agent): Build a custom Scraper based on Extractor — only for pages with identical layouts (ideal for scale).
🎁 Prompting Best Practices
Extract insights, summaries, or any other form of derived data:
- Prompt: Extract all quotes and explain the context in which each quote was made in this article
- Prompt: Analyze the company’s website and list all the primary business qualities and marketing advantages they emphasized
Get data under certain conditions:
- Prompt: Analyze the listing and return only products that cost less than $100
- Prompt: Extract the number of product reviews and the text of the most recent review only
Process data before putting it into the output:
- Prompt: Extract the product’s discount percentage; otherwise, put 'no discount'
Format data presentation in the output:
- Prompt: Scrape the price but save it in the output without the '$' sign
Get data even if you're unsure of its amount:
- Prompt: Extract all available contact information along with associated names from this page